Парсер частотности WordStat
Парсер частотности WordStat
Парсер частотности WordStat. Помогает быстро собрать частотность запросов по большому ядру.
Что подавать на вход?
Список запросов для парсинга. В виде *.xlsx файла (запросы в один столбец, остальные пустые) или списком в поле, каждый запрос с новой строки
Код региона. По умолчанию - поле пусто, сбор идёт без уточнения региона
Тип устройства. Все, мобильные, планшеты, телефоны. По умолчанию - все.
Режим сбора. Можно собирать 5 вариантов:
- поисковая фраза
- "поисковая фраза"
- "!поисковая !фраза"
- "[поисковая фраза]"
- "[!поисковая !фраза]"
Что в результате?
Файл со списком собранной частотности для каждого запроса
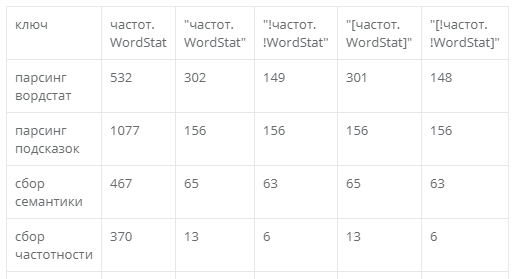
В первом - ваш запрос
Во втором и далее - соответствующая цифра частотности wordstat (если соответствующий тип частотности выбран)
FAQ по парсеру частотности
Q: Поддерживает ли парсер другие языки?
A: Да, русский, белорусский и английский алфавиты поддерживаются
Q: Поддерживает ли парсер операторы wordstat?
A: Нет, не поддерживает. Вы можете выбрать только варианты сбора из списка.
Q: Я проверяю руками, цифры другие! И запросов больше!
A: Проверьте выставленные регион и устройство. При сужении региона или типа устройства меняются цифры частотности запроса и количество отдаваемых запросов.
Q: У каждого варианта написано +XX к стоимости. Если я выберу один вариант - стоимость будет в 2 раза больше тарифа?
A: Нет, если вы не выберите ни один вариант стоимость будет 0 (и парсинга не будет, соответственно). Каждый выбранный вариант стоит в соответствии с вашим тарифом (стоимость сбора на тарифе*число выбранных вариантов).
Например, если вы собираете один вариант запросов на тарифе "Чатланин", стоимость сбора по 1 запросу будет 2,5 копейки. Если два варианта - 5, три - 7,5. И так далее.