Парсер поисковых подсказок Яндекса
Парсер поисковых подсказок Яндекса
Зачем он нужен?
- Быстро собирать семантику. Даже ту, которой нет в вордстате
- Быстро валидировать большой массив запросов
На вход подается запрос или список запросов, для которых вы хотите подобрать релевантные слова и словосочетания. Подбор будет выполняться для каждого запроса в отдельности.
Как работает?
Есть три режима работы: стандартный, валидация запросов и отладочный.
В стандартном режиме это обычный парсер подсказок с фильтрацией так называемых автокомплитов (запросов, которые сгенерированы автоматически и отсутствуют в базе подсказок Яндекса). Работают переборы по символам, а также возможность сразу подавать на вход ранее найденные запросы.
В отладочном режиме парсер выводит все найденные подсказки, а также их скрытые параметры. Подробнее об этом тут:
В режиме валидации парсер делает несколько специально сконструированных запросов чтобы понять - содержится ли поданная на вход фраза в поисковых подсказках (без учёта автокомплитов) или нет.
Как с этим работать?
- Выбрать режим работы. Для простого парсинга - стандартный, для валидации запросов - валидацию. Для специальных задач (вы знаете зачем) - отладочный режим.
- Выбрать регион сбора подсказок. По умолчанию 213 - Москва.
- Выбрать количество итераций сбора (это когда найденные запросы вновь подаются на парсинг). По умолчанию 1 итерация - это без повторного парсинга.
- Выбрать перебираемые символы. Русский алфавит, латинский, цифры.
- Загрузить запросы списком в *.xlsx файле (в один столбец, без дополнительных столбцов) или списком вставить в форму (каждая фраза с новой строки).
Дополнительные опции:
“Собирать порно-подсказки”. Если вы двигаете секс-шоп или прочие непотребства - вам нужна эта галочка. Обычно порно-подсказки скрыты.
“Добавлять пробел к базовой фразе”. По умолчанию включено и ко всем базовым фразам добавляется пробел. Но если вы, например, хотите парсинг с перебором более одного символа, то придётся прибегнуть к данной настройке.
Что на выходе?
Если вы “заказывали” обычный парсинг, то на выходе получите такой вот файл:

В нём всё просто. Первый столбец - базовая фраза, второй - найденная фраза.
Если вы использовали “валидацию”, то выходной файл будет таким:
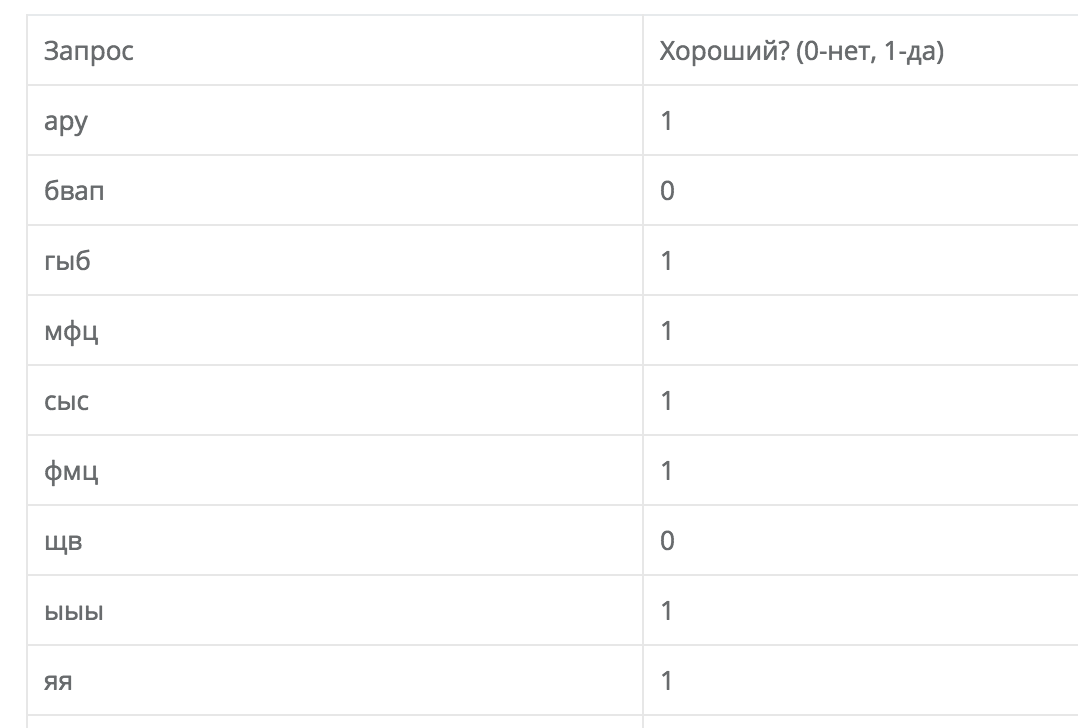
Первый столбец - ваша фраза, второй - удалось ли её найти в подсказках.
Ну и, наконец, для парсинга в отладочном режиме выходной файл будет выглядеть так:

На этом скриншоте:
Src - исходный запрос.
Wrk - составленная при переборе/итерации фраза.
Sug - Найденная подсказка
Pos - Позиция найденной подсказки
SgType - Специальный параметр подсказки, подробнее про него (и остальные) в статье о подсказках
Type - Тип подсказки (если есть)
Cont - Контент подсказки (если есть)
Iter - Номер итерации, на которой получена подсказка
FAQ по Парсеру подсказок
Q: Зачем оно вообще надо?
A:Чтобы быстро спарсить много семантики (которой может не быть в wordstat или в не-сезон) или быстро почистить ядро через режим валидации.
Q: А автокомплиты? Парсер их вычищает?
A: Да, в стандарном режиме и валидации подсказки-автокомплиты автоматически удаляются. В отладочном режиме они выводятся, но вы их сможете узнать по соответствующему sgtype
Q: Парсер выдал пустой результат!
A: Проверьте руками, есть ли подсказки по этим запросам. Такое чаще всего случается из-за опечаток во входных запросах. Также проверьте, включили ли вы парсинг порно-подсказки, если собираете семантику для взрослых тематик.
Q: А можно собирать подсказки с перебором более 1 символа?
A: Можно, но не полностью автоматически. Запустите первый парсинг в отладочном режиме. В результате выберите основы подсказок для которых нашлось 10 саджестов и их подайте на вход заново как входные запросы. Не забудьте убрать галочку "Добавлять пробел к базовой фразе" на второй и далее итерациях. Повторяйте столько раз, сколько требуется в вашей тематике.