Кластеризация запросов по данным serp. Документация.
Это модуль, который позволяет сгруппировать запросы на основании топов Яндекса или Гугла. Такая группировка позволяет понимать, какие запросы могут быть продвинуты на одной странице или же просто ускоряет и упрощает разбор ядра.
Зачем нужна кластеризация?
- Быстро и эффективно разобрать свое семантическое ядро.
- Понять, какие запросы могут вести на одну страницу.
- Упростить устранение «левых» запросов из ядра.
- Использовать кластеризацию для построения продвигаемой структуры.
Метод кластеризации - hard. Soft-кластеризация реализована в онлайн-маркерах.
Что подается на вход?
Список запросов (в форме или *.xlsx файлом).
В файле должен быть один столбец, в котором содержатся запросы. В форме — каждый запрос с новой строки. В запросах должны быть только печатные символы (русские/английские буквы (также допускаются буквы белорусского и украинского языков), цифры, пробел, дефис, «/». Все лишние символы автоматически удаляются, как и дубликаты запросов.
Скачать пример входного файла (бесплатно, без смс и регистрации) === ТЫЦ
Помимо самого файла, можно поменять настройки задачи:
- Метка задачи. Опционально, только для вашего удобства.
- Поисковая система - Яндекс или Google. По её топам будет проводиться кластеризация. В случае выбора Google нельзя будет выбрать определение геозависимости и коммерции в качестве дополнительных данных.
- Язык задачи. На каком языке запрашивать SERP - на русском или английском.
- Страна для Google. Только при выборе Google как поисковика для кластеризации. Выбираете страну из списка.
- Регион Google. Только при выборе Google как поисковика для кластеризации. Выбираете регион из списка.
- Код региона для кластеризации по Яндексу. Только при выборе Яндекса как поисковика для кластеризации. По умолчанию стоит 213 = Москва. Кластеризация будет выполняться по топам указанного региона.
- Тематическая классификация запросов. По умолчанию галочка стоит. Бесплатно, но сильно замедляет задачу. Документация по тематическому классификатору.
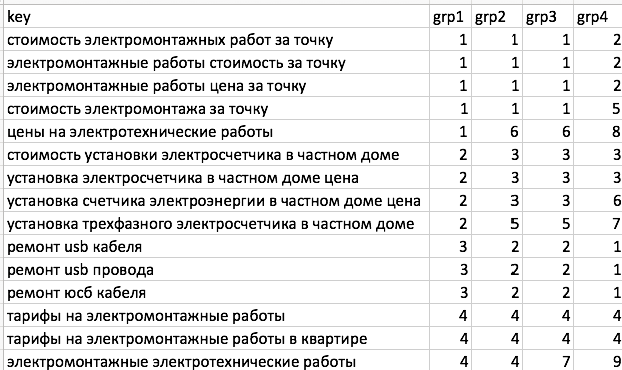
- Использовать альтернативный формат групп. Изменяет принцип нумерации групп (только правила присвоения номеров, группы остаются только такими же). Что это и зачем надо — ниже. (Если вам лениво разбираться — не ставьте эту галочку. Она не влияет на алгоритм группировки)
- Определение ГЕО-зависимости запроса. Только при выборе Яндекса как поисковика для кластеризации. Дополнительно определяет геозависимость каждого запроса.
- Определение коммерческости запроса. Только при выборе Яндекса как поисковика для кластеризации. Дополнительно определяет коммерческость каждого запроса.
- Сбор частотности. Дополнительно определяет частотность каждого запроса с выбранными вами набором операторов. Стоимость зависит от вашего тарифа.
- Регион для сбора частотности. Вводится отдельно, может отличаться от региона кластеризации. Например, частый случай - кластеризация по Москве, а частотность - по России.
- Домен для поиска релевантных страниц. Если данный домен найдётся в топ-10 по запросу, в файле с результатом будет найденный по этому запросу УРЛ данного домена.
- Оповещение на почту. Если задачу ждать долго и вы хотите узнать сразу как будет готово.
Результат кластеризации
В файле содержатся столбцы:
key — grp1 — grp2 — grp3 — grp4 — Частот. Wordstat — mord — tema — geo — comm — url
Столбец key — это сам запрос.
grp1 — это наиболее широкая группа (сформировання по 3м урлам). Это означает, что все запросы, имеющие одинаковый номер группы в столбце grp1, относятся к одной группе. Группа формируется по принципу «существует как минимум 3 урла, которые присутствуют в топ-10 по каждому из запросов группы».
Группы grp2-4 созданы по аналогичному принципу, но минимум урлов для объединения у них, соответственно, 4-6.
Группы grp1 нумеруются от наибольшей к наименьшей. Самая большая (по количеству запросов в ней) получает номер 1. Группа поменьше — 2, и так далее.
Группы grp2-4 нумеруются следующим образом. Самая большая подгруппа предыдущей группы наследует её номер. Остальные нумеруются большими числами (от 10000). Выглядит это так:
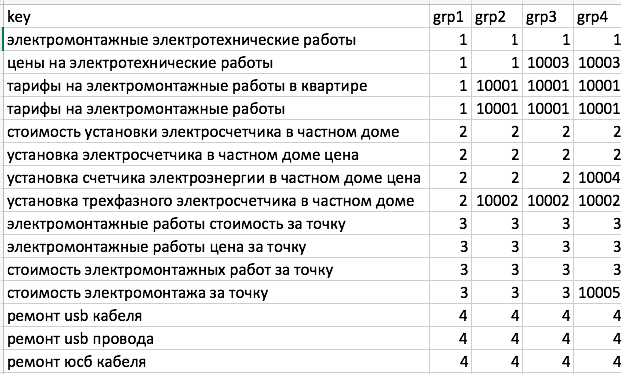
При включенной галочке «альтернативная нумерация групп», группы grp2-4 нумеруются по аналогии с grp1. Т.е. самая большая grp2 получает номер 1. Поменьше — номер 2. Аналогично grp3 и grp4. Выглядит это так:
Дополнительные данные кластеризации:
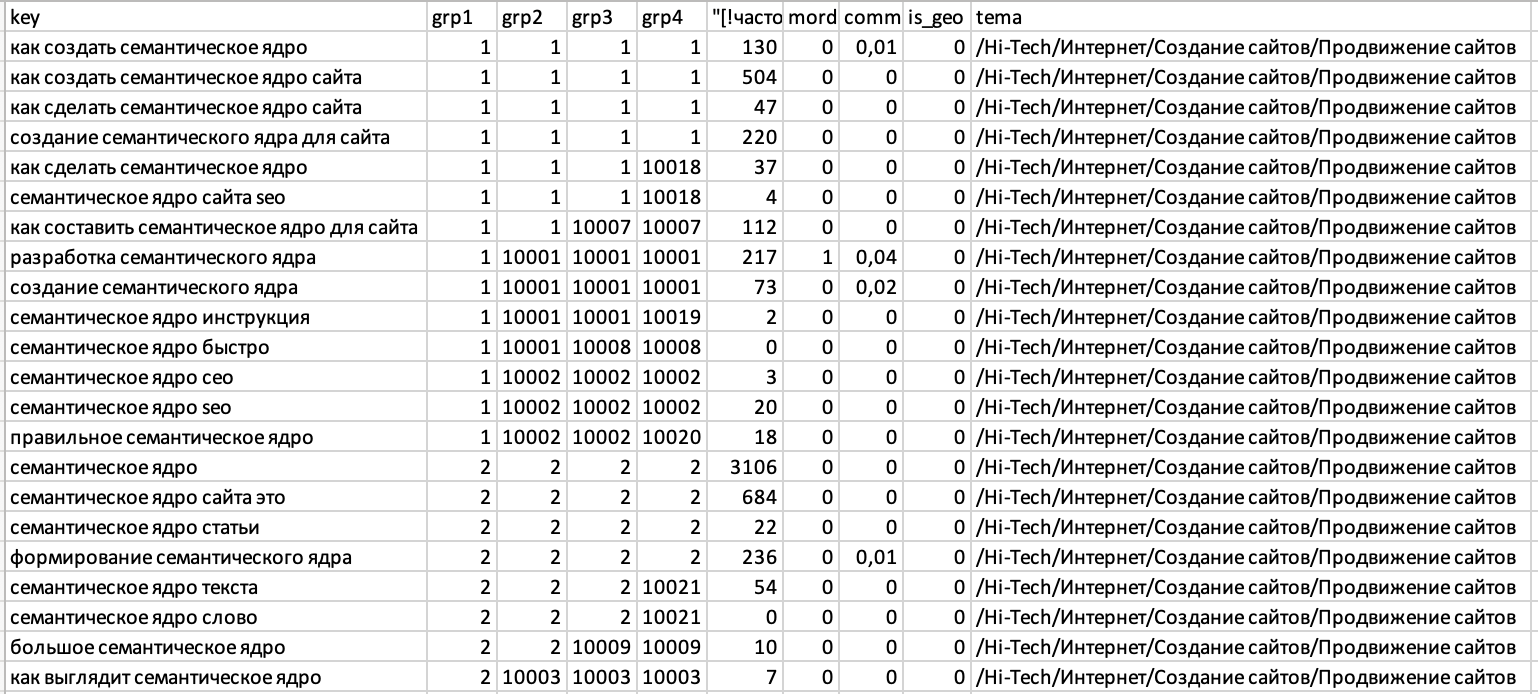
- "[!частот. !WordStat]" - частотность вордстат запроса по указанному в задаче региону. Столбцов с частотностью может быть несколько, если вы решили собрать несколько её типов сразу. например - "частот. WordStat" и "[!частот. !WordStat]".
- mord - количество главных страниц (морд) в топ-10.
- tema - результат тематической классификации запроса. Выводится только одна тематика, которую классификатор посчитал наиболее подходящей
- comm - результат работы коммерческого классификатора. Число в интервале от 0 до 1. 0 - полностью некоммерческий, 1 - полностью коммерческий.
- is_geo - результат работы гео-классификатора. 1 - запрос геозависимый, 0 - геонезависимый
- url - найденный в топ-10 урл сайта. Если урла не найдено - 0.
Как использовать кластеризатор
- Подготовьте своё ядро к кластеризации. На кластеризацию необходимо отправлять очищенное ядро (прошедшее через все стадии очистки - валидацию через подсказочник, чистку по стоп-словам, тематическую классификацию, минимальный wordstat).
- Если вы делаете кластеризацию для построения структуры, выполните отсечение низкочастотных запросов. По планке wordstat “[!]” 30 или хотя бы 10. Это отсчечение позволит сформировать более плотные и правильные кластеры.
- Для Яндекса важен выбор региона в случае работы в региональных тематиках с гео-зависимыми запросами. Для остальных случаев (работа на всю Россию или в вашей тематике в основном ГНЗ запросы - оставляйте дефолтный 213 регион).
FAQ по кластеризатору
Q: Запросы “розовый слон” и “купить розового слона” попали в один кластер. Это значит их можно вместе продвигать?
A: Возможно. Это означает, что у них в топе есть достаточное число одинаковых урлов. И их продвижение на одной странице в принципе возможно. Но это не значит, что их обязательно сажать на одну страницу. Бывают исключения.
Q: На что смотреть? grp1, grp2, … Непонятно!
A: Чаще всего на grp1, реже на grp2. grp3 и grp4 используются крайне редко. Если кластер большой, то смотрите как он разбивается по grp2. Если это разбиение имеет какую-то явную логику (дополнительное слово, коммерческость запроса, и.т.д.) на это стоит обратить внимание. Также grp2 и grp3 могут использоваться в низкоконкурентных тематиках, где объединение по трём урлам даёт кластеры слишком низкого качества.
Q: Какой регион выставлять для кластеризации?
A: Если у вас общероссийский проект - выставляйте 213 - Москву. Если узкий региональный - ваш регион. Если ваши запросы геонезависимые, регион не важен.
Q: В одном кластере запросы с высокой и низкой коммерческостью? Как такое может быть?
A: Это довольно редкий случай. Это означет, что кластер сформирован по урлам, содержащим смешанный интент. Или - по комм и инфо урлам одновременно. В этом случае выберите один интент - комм или инфо - и двигайте его.
Q: А под Google?
A: Под Google кластеризатор так же работает. Доступные языки - русский и английский. Но параметры частотности и геозависимости не собираются для него. Также тематическая классификация доступна только для русского языка.