Тематический классификатор - зачем он нужен, и как его правильно применять.
Что такое тематический классификатор?
Тематический классификатор - это еще один способ поменьше работать для оптимизатора. Попробуйте решить "простую" задачку. Вы напарсили запросы, и у вас получились вот такие:
- аквамарин
- аквамарин 2
- аквамарин 3
- аквамарин 4
- аквамарин 5
- аквамарин сочи
- аквамарин владивосток
- аквамарин казань
И вам нужно понять, что из них относится к вашей тематике, а что - лишнее. Допустим, ваша тематика - отели. Что вы будете делать? Скорее всего - зайдете в выдачу и посмотрите. Но так вы поступите, если запросов у вас десяток или два. А если их тысячи? Или - десятки тысяч? Метод "зайти и проверить каждый" работать перестаёт. И тут на помощь приходит тематический классификатор, который распределит эти запросы за вас. Вот как он справляется с представленным выше списком:

Как видим, отельной тематике соответствуют всего 3 запроса. "Аквамарин 3" - это бизнес-центр, "Аквамарин Владивосток" - это строящийся ЖК. А "аквамарин казань" - и вовсе ювелиры. Можете самостоятельно сходить в выдачу и проверить. Каким образом классификатор понимает, какой запрос к чему относится? Он делает то же самое, что и человек - идет в выдачу и смотрит что в ней есть. Затем сравнивает найденное в выдаче с некоторыми "эталонными" коллекциями. При этом анализируются не урлы сайтов или какая-то информация по ним, а сами текстов заголовков и сниппетов. В общем случае процесс выглядит так:
Запрос выдачи → Разбиение на слова → Построение вектора → Сравнение с векторами тематик.
Как это применимо на практике? Когда мы начинаем разбор какой-то новой ниши, или сбор семантики для сайта, мы всегда начинаем с массового парсинга запросов. Запросы мы эти получаем из вордстата, подсказок, вебмастера, метрики или баз. При любом методе сбора, мы всегда будем получать как соответствующие нашему сайту запросы, так и нет. Рассмотрим на достаточно хардокрном примере. Допустим, у нас есть автопортал, и мы хотим сделать раздел про BMW ALPINA. Мы обращаемся к вордстату, подавая к нему запросы alpina и альпина. И получаем вот такой интересный результат:
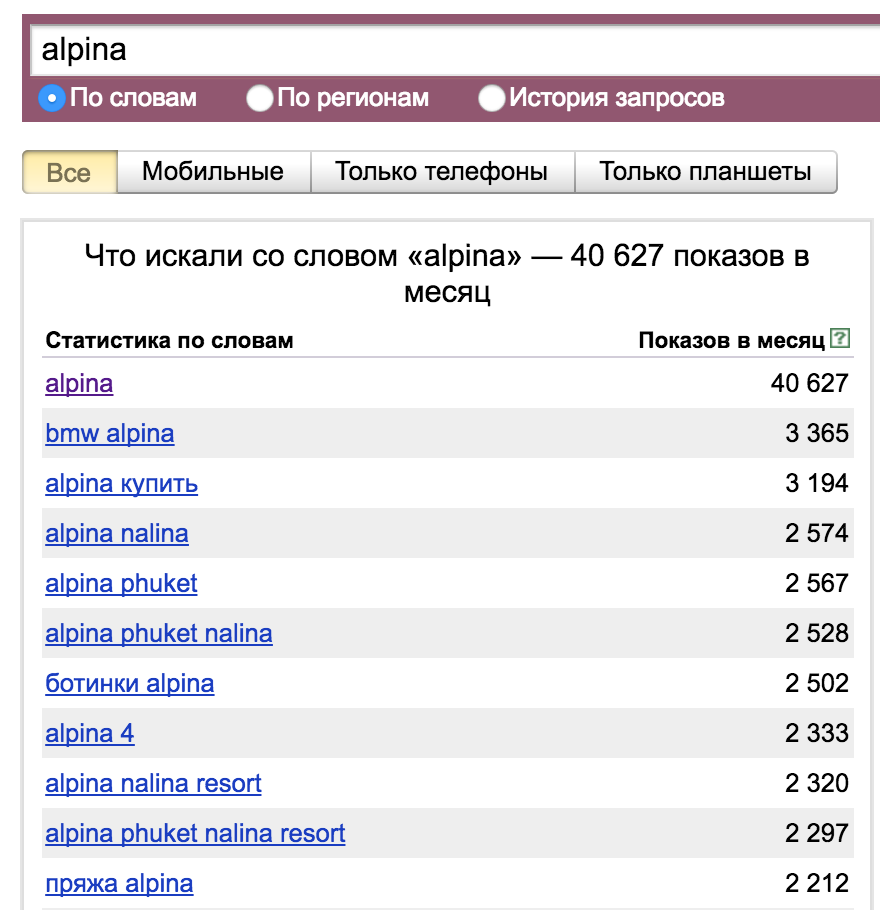
Оказывается, помимо BMW, alpina может быть чем угодно. Ботинками, отелем, даже пряжей. Посмотрим, как с такой задачей справится классификатор. Загружаем в него спарсенные запросы, фильтруем по вхождению "BMW" в тематике и получаем вот такой список:

Как видно, качество очень хорошее. Может показаться, что один запрос там лишний - а именно "вино альпина". Но если открыть выдачу и почитать, то станет понятно что нет, он очень даже к месту:
А в багажнике - еще один маленький штрих - вы найдете пристегнутый ремешками, деревянный ящичек. Внутри несколько бутылок вина. Компания Alpina всем клиентам обязательно дарит несколько бутылок с собственных виноградников. Вино - хобби хозяина фирмы Буркарта Бовенсайпена.
Если бы мы искали не "бмв", а что-то другое, то классификатор нам опять же помог бы. Например, мотоциклы:

Или автохимию:
(оказывается, альпина - это еще и бренд моторного масла).

Таким образом, в классический метод сбора семантики добавляется ещё один элемент. После первичного сбора ядра мы выполняем тематическую классификацию запросов и отсеиваем нетематичные:
Первичный сбор запросов → Тематическая классификация → Кластеризация/постраничное.
Ещё одно применение - это почистить текущее ядро. Причем классификатор справляется даже с теми случаями, где человек запрос оставит. Например, если мы продвигаем сайт про гостиницы, то казалось бы что криминального в запросе "гостиница чайка ярославль"? Однако, классификатор упрямо относит его в "/Бизнес/Недвижимость/Аналитика". Почему так происходит? Давайте заглянем в выдачу:
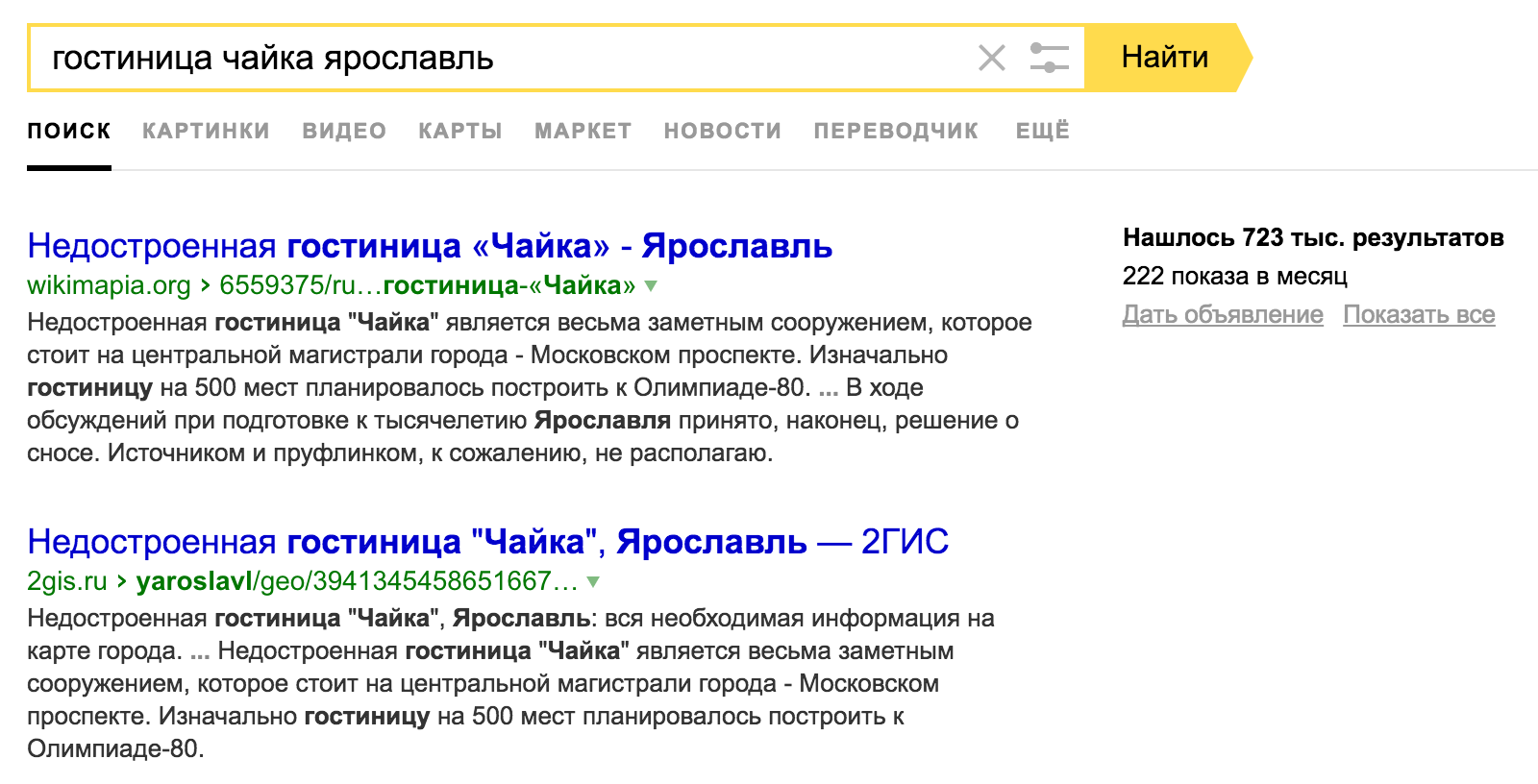
Оказывается, это недостроенная гостиница и для сайта бронирований отелей она совершенно не подходит. И такой пример далеко не единичный. Что может быть не так с запросом "давидыч гостиница самары"? А почему "отель двух миров уфа" лучше выкинуть из ядра? Ответы на эти вопросы можно получить только зайдя в выдачу. Или же - воспользовавшись классификатором.
Где пощупать тематический классификатор самому?
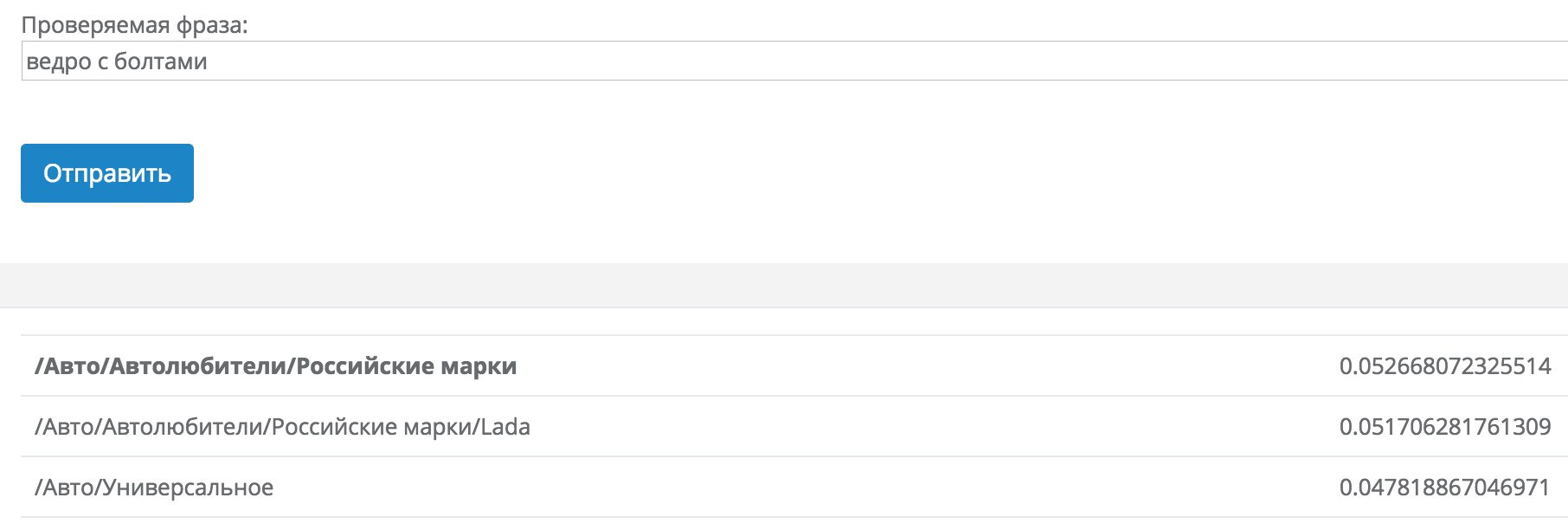
1) У нас есть шикарная полностью бесплатная демка классификатора: https://just-magic.org/serv/demo_temakl.php
Можно погонять отдельные запросы и посмотреть как классификатор справляется с вашей тематикой (работает только с запросами, урлы не разбирает).
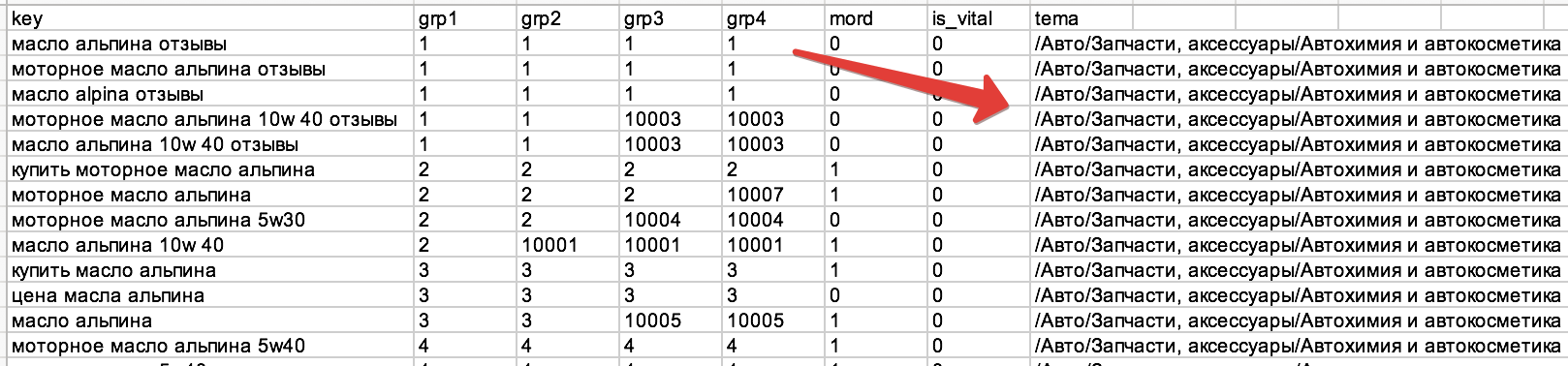
2) Тематический классификатор встроен в кластеризатор: https://just-magic.org/serv/grp_onl.php
В столбце "tema" выводится результат классификации:
3) Тематический классификатор есть отдельным модулем: https://just-magic.org/serv/temakl.php
Зачем он нужен отдельным модулем, если уже встроен в кластеризатор?
1. Он дешевле. Ровно в 2 раза дешевле, чем кластеризация. Что очень актуально для чистки ядра перед кластеризацией или расширением.
2. У него есть опция выгрузки расширенных данных. Это очень актуально для запросов, которые могут быть отнесены сразу к нескольким категориям. Например, куда отнести запрос "диета для фитнеса"?
/Дом/Кулинария/Диеты?
/Дом/Мода и красота/Фитнес?
/Дом/Здоровье/Здоровый образ жизни?
Все три темы подходят для запроса. Расширенные данные выгружают не только 1, наиболее релевантную тему, а 10 релевантных с их условными весами, что упрощает работу с подобными запросами.
3. Он умеет работать не только с запросами, но и с урлами (этой опции нет и в демке). Допустим, вы хотите пробить своих/потенциальных доноров на тематичность. Просто загрузите список урлов (с http/https), анализатор сам распознает в них урлы и присвоит тематику:

Внимание! Анализатор определяет тематику не сайта, а конкретной страницы. Как пример - анализ трех разных категорий с Яндекс.Маркета:

Подведем итог. Тематический классификатор - очень удобный инструмент для массовой фильтрации запросов. Он может эффективно применяться как при фильтрации запросов при подборе ядра, так и для проверки текущего. Пользуйтесь классификатором, и ваши волосы будут мягкими и шелковистыми ядра станут лучше и чище.