BERT - прорыв в обработке естественного языка поиском?
Google в декабре объявил о релизе алгоритма BERT на Россию. Как и в случае с Палехом и Королевым Яндекса заявляется о революционных изменениях в понимании запроса, соответствия запросу документу. И приводятся достаточно убедительные примеры.
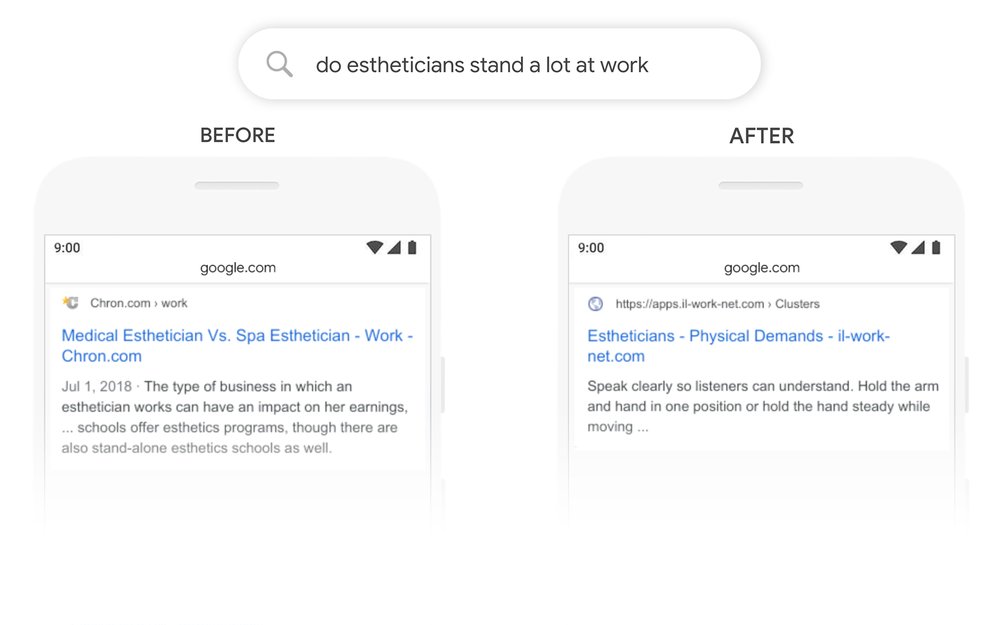
Так ли это на самом деле, является ли BERT аналогом Палеха/Королева и действительно ли поиск научился понимать смысл запроса? Давайте разбираться.
Длительное время в анализе текстов поиск опирался лишь на ключевые слова. Фактически, несмотря на повсеместное использование машинного обучения в ранжировании, факторы текстового поиска до последних лет оставались родом из 80х. Это были вариации на тему известных сеошникам TF-IDF и BM25. Конечно же, использовались они не в чистом виде. Могли использоваться различные системы весов, не только IDF. Были попытки расширения за счет использования синонимов. Использовались специальные версии BM25, которые учитывали пары слов. Но ключевой принцип при этом оставался один - для расчета фактора применялись лишь слова запроса и те же слова, содержащиеся в документе. Причем - без учета их взаимного расположения, почти вся информация о порядке слов просто не использовалась.
Давайте подумаем, какая информация содержится в типичном документе. Это слова в определенной последовательности, плюс знаки препинания. Что делали старые текстовые факторы? Из всего массива слов документа исключались слова, не содержащиеся в запросе. То есть - большая часть документа даже не рассматривалась. А также, терялась по большей части информация о последовательности слов. Как-то ее учитывали биграммы (пары слов) и фичи с более длинными вхождениями. Но это даже не костыли, а лишь небольшое расширение, как и синонимы.
Следующим шагом в развитии поиска стало применение DSSM (Deep Semantic Similarity Model), изначально разработанная Microsoft

Эта модель была применена в 2017 году, когда Яндекса совершил качественный скачок в виде Палеха. Теперь алгоритм стал учитывать не только слова запроса, а вообще все слова содержащиеся в документе (документом в случае Палеха был тайтл, но это не принципиально). Это был действительно качественный прорыв, позволивший не только привнести радикально новую фичу в закостенелые текстовые факторы, но и начать решать проблему ранжирования в ситуациях когда слова запроса могут не содержаться в документе-ответе.
И вот, Гугл в 2019 году презентует вроде бы похожую на Палех-Королев технологию. BERT - Bidirectional Encoder Representation from Transformers.
Начнем с расшифровки аббревиатуры. Самое важное в ней - Transformers. Это новая архитектура нейросетей, которая была представлена в 2017 году. В отличие от предшественников, являвшихся развитием рекуррентных нейросетей, в Transformers использован принципиально новый механизм - Attention, который позволяет взаимодействовать с другими словами в предложении. Подробнее об Attention - в блоге google ai и в статье attention is all you need.
Encoder Representation - отражает еще одну суть алгоритма. Фактически BERT это автокодировщик (autoencoder), один из классов нейросетей обучаемых без учителя. Обучение BERT проходит через маскирование определенного процента слов, которые затем сеть пытается угадать. В BERT используется Masked LM (MLM): В тексте случайные 15% слов заменяются токеном [MASK], а нейросеть пытается по окружающим словам и контексту угадать какие слова были скрыты в каждом случае.
И наконец Bidirectional - означает двунаправленный анализ последовательностей слов. Та же самая архитектура Transformers использовалась в GPT от OpenAI и фактически BERT является ее развитием. В отличие от GPT, в BERT связи между словами рассматриваются как слева-направо, так и справа налево:
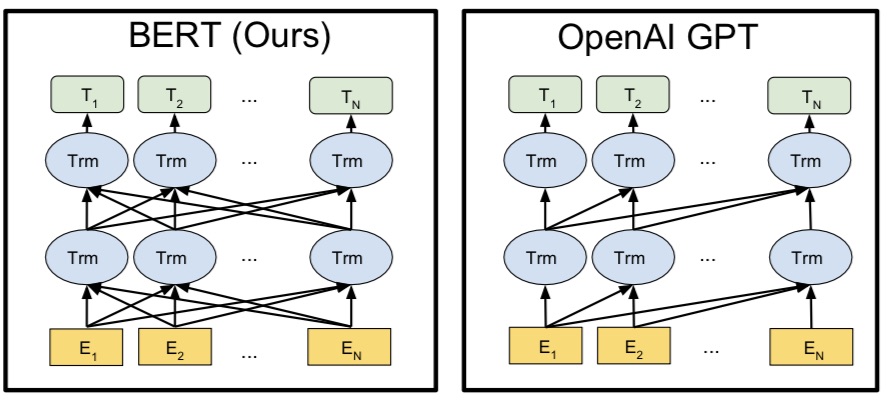
Чем BERT отличается от Палеха/Королева?
Если вы читали подробное описание работы "палеха" на Хабре, то уже поняли что общего у этих алгоритмов только использование нейросетей и deep learning.
Первое отличие - архитектура. В Палехе/Королеве взяли за основу DSSM (Deep Structured Semantic Models) от Microsoft. Это более старая архитектура, которая позволяет оперировать различными токенами (которые могут быть как результатом word hashing, так и словами и биграммами) и сильно ее допилили под свои нужды. Эта архитектура в принципе не оперирует той полнотой данных, что и BERT. В BERT на вход помимо слова подается сегмент (предложение) и номер слова в тексте:
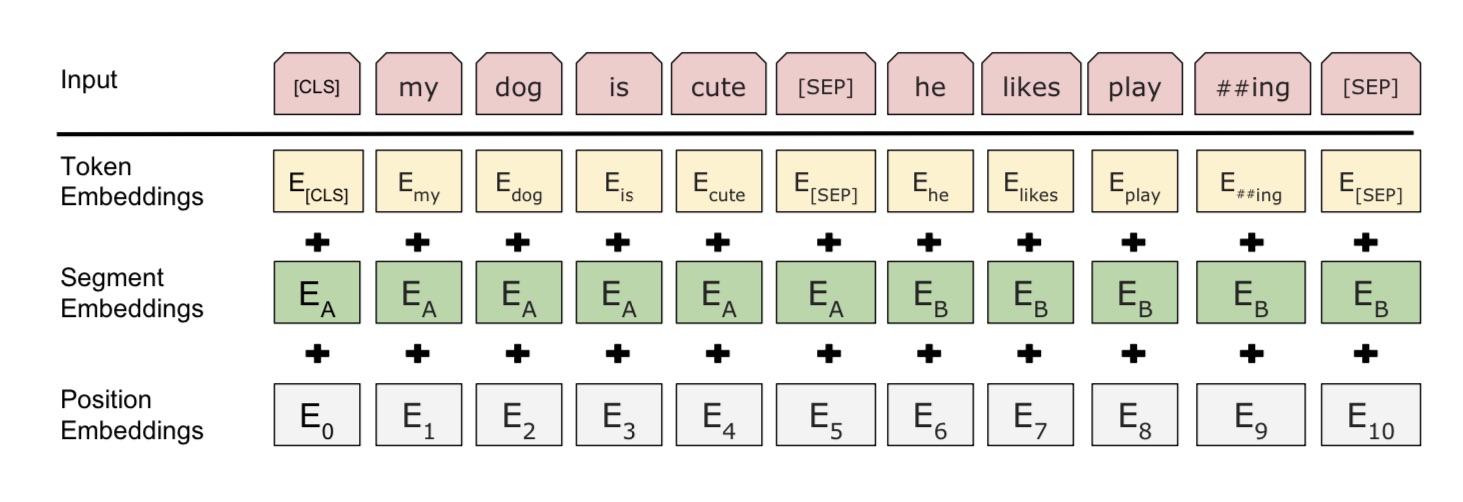
Второе важное отличие - это Transfer Learning. Палех/Королев изначально обучали решать конкретную задачу. В Transfer Learning нейросеть сперва учится решать простую задачу на большом объеме данных, а затем предобученная модель используется в более специфических задачах. Палех/Королев сразу обучали решать задачу соответствия заголовка/документа запросу. BERT же обучают через маскирование слов в текстах:
Что умеет BERT?
Главное что нужно понять, BERT - это не решение конкретной задачи. Это платформа, позволяющая за счет дополнительной надстройки пары слоев нейронов решать самые разные задачи в области обработки естественного языка.
Рассмотрим задачу, которую "Палех"/"Королев", да и нынешние антиспам-алгоритмы решить не в состоянии. Есть два идущих подряд предложения. Они логически связаны и одно является продолжением другого? Или это просто два случайных предложения? BERT позволяет решить данную задачу, причем показывает state-of-the-art результат. Например:
1) Установка пластиковых окон с гарантией результата. Бесплатный выезд для замера.
2) Установка пластиковых окон с гарантией результата. Все товары для фидерной ловли.
В первом случае BERT даст высокую вероятность второго предложения как продолжения первого. Во втором - околонулевую (точнее - должен дать, я не проверял).
Может ли BERT как Палех/Королев находить документы, релевантные запросу? Да, конечно. И даже более того - BERT может находить конкретное место в тексте, в котором содержится ответ на поисковый запрос. Эта опция уже активно применяется при формировании featured snippet. Однако, тут же проявляется и фундаментальный недостаток текущего уровня обработки естественного языка. Алгоритм может найти ответ в тексте, но не может понять правильный он, ошибочный или шуточный. Наглядно иллюстрирует это один из featured snippet, быстро ставший мемом:
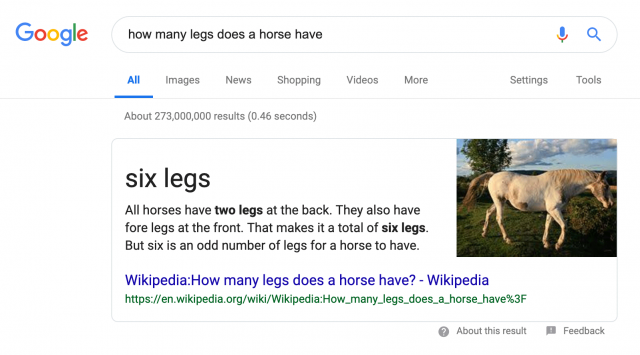
Для тех кто не очень хорошо владеет английским - здесь игра слов. Fore - означает «передние», но произносится так же как «four» - четыре.
Подытожим?
BERT является качественным скачком в задачах текстового поиска. Это реализация новых подходов Transformers и Transfer Learning, которые в последние годы произвели мини-революцию в задачах NLP (обработки естественного языка). Потенциально он умеет куда больше чем Палех/Королёв и способен значительно улучшить качество текстового поиска. Однако, BERT не лишен недостатков. Первый и самый очевидный кроется в методе обучения - нейросеть пытается угадать каждое слово в отдельности, а значит теряет в процессе обучения некоторые возможные связи между словами. Другой - нейросеть обучается на masked токенах, а затем используется для принципиально иных задач, более комплексных. На данный момент статус state-of-the-art модели уже пошатнулся, на пятки наступает XLNet и другие альтернативные архитектуры. Но в целом можно сказать, что хотя алгоритмы все еще не умеют понимать запрос и текст, они все лучше учатся угадывать. И BERT - это следующая ступенька развития алгоритмов, значительно опережающая Палех/Королев.
P.S. Для тех кто хочет улучшить свое понимание применения машинного обучения в поиске, в марте я провожу ежегодный курс "Палево", в котором теперь один день полностью посвящен ML: http://chekushin-seo.ru/